
Objetivos de aprendizaje
Tras completar este capítulo, podrás:
- Comprender cómo se utiliza el aprendizaje automático para resolver problemas del mundo real.
- Comprender el tipo de algoritmos y marcos de aprendizaje automático que se utilizan para construir modelos de aprendizaje automático.
Introducción a la analítica y al aprendizaje automático
El análisis en el aprendizaje automático se refiere al proceso de analizar e interpretar datos paraobtener información valiosa, tomar decisiones informadasy mejorar los modelos de aprendizaje automático. Este proceso implica varias técnicas y herramientas para explorar, visualizar y comprender los datos, así como para evaluar el rendimiento de los modelos de aprendizaje automático.
Analicemos cómo conceptos como la Inteligencia Artificial (IA), el Aprendizaje Automático (AA) y el Aprendizaje Profundo (AP) se relacionan con las técnicas analíticas:
- Inteligencia Artificial (IA): La IA es un campo amplio de la informática centrado en la creación de máquinas inteligentes que pueden simular el comportamiento humano. En el contexto de la analítica,AI Estas técnicas pueden utilizarse para analizar datos, realizar predicciones y automatizar los procesos de toma de decisiones.Las herramientas analíticas basadas en inteligencia artificial pueden procesar grandes volúmenes de datos, identificar patrones y generar información valiosa para respaldar la toma de decisiones.
- Aprendizaje automático (ML):ML es un subconjunto de la IA que se centra en el desarrollo de algoritmos y modelos estadísticos que permiten a las computadoras aprender de los datos y hacer predicciones o tomar decisiones basadas en ellos.En analítica, las técnicas de aprendizaje automático se utilizan para construir modelos predictivos que pueden analizar datos y hacer predicciones sobre resultados futuros. Las técnicas de aprendizaje automático más comunes incluyen regresión, clasificación, agrupamiento y aprendizaje por refuerzo.
- Aprendizaje profundo (DL):DL es un subconjunto del aprendizaje automático que utiliza redes neuronales artificiales para modelar y procesar patrones complejos en grandes cantidades de datos.Las técnicas de DL son particularmente efectivas para tareas como el reconocimiento de imágenes y voz, el procesamiento del lenguaje natural y los sistemas de recomendación. En analítica,El aprendizaje profundo se puede utilizar para analizar datos no estructurados, como imágenes, texto y audio, y extraer información valiosa.
La relación entre AL, ML y DL se puede visualizar como se muestra en la Imagen 1.1.
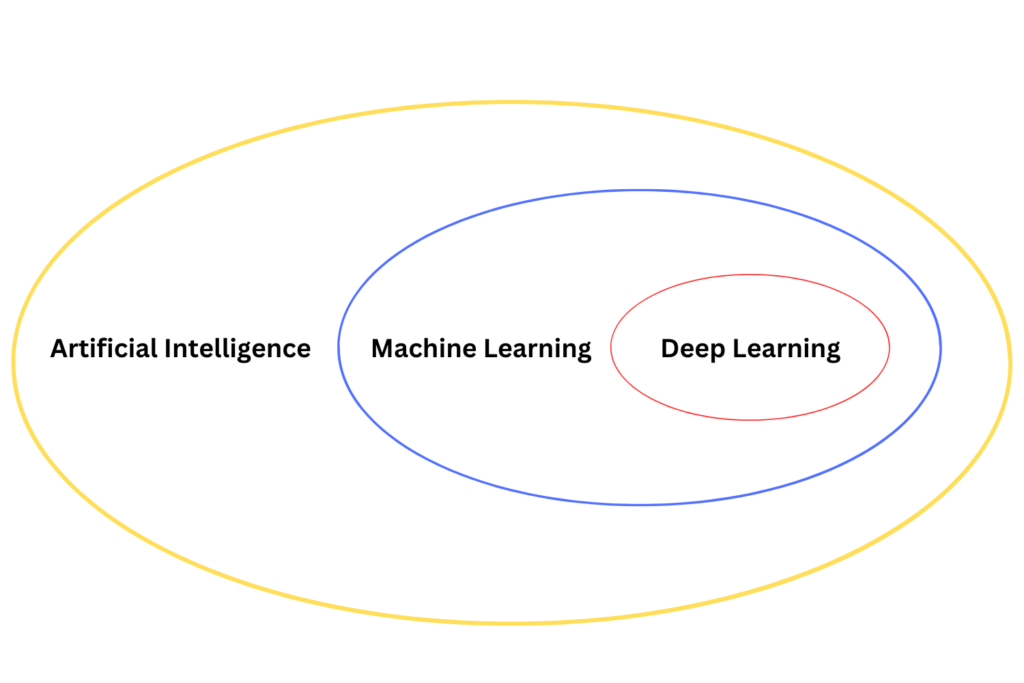
Lo importante es que todos ellos son algoritmos, que no son más que conjuntos de instrucciones utilizadas para resolver problemas del mundo real.
Los algoritmos de aprendizaje automático se dividen en cuatro categorías, tal como se define a continuación:
- Algoritmos de aprendizaje supervisado
Supervisado Los algoritmos de aprendizaje aprenden de datos de entrenamiento etiquetados para hacer predicciones o tomar decisiones sobre datos nuevos.Los algoritmos comunes incluyen la regresión lineal (para predicciones continuas), la regresión logística (para clasificación binaria), los árboles de decisión (tanto para clasificación como para regresión), los bosques aleatorios (un método de conjunto para una mayor precisión), las máquinas de vectores de soporte (para clasificación binaria y regresión), los k vecinos más cercanos (tanto para clasificación como para regresión), el clasificador bayesiano ingenuo (un clasificador probabilístico) y las redes neuronales (algoritmos versátiles inspirados en la estructura del cerebro).
Aquí tienes un breve ejemplo de cómo se puede utilizar un algoritmo de aprendizaje supervisado, concretamente la regresión lineal:
Supongamos que tenemos un conjunto de datos con información sobre casas, como su tamaño (en pies cuadrados) y precio (en rupias). Queremos crear un modelo que pueda predecir el precio de una casa en función de su tamaño.
- Conjunto de datos: Tenemos un conjunto de datos con varios ejemplos de casas, cada una con un tamaño (característica de entrada) y un precio (variable objetivo).
- Entrenamiento: Utilizamos este conjunto de datos para entrenar un modelo de regresión lineal. Durante el entrenamiento, el modelo aprende la relación entre el tamaño de una casa y su precio ajustando sus parámetros.(pendiente e intersección) para minimizar el error entre sus predicciones y los precios reales en los datos de entrenamiento.
- Predicción: Una vez entrenado el modelo, podemos usarlo para predecir el precio de una casa nueva en función de su tamaño.El modelo utiliza la relación aprendida para hacer predicciones sobre datos nuevos y no vistos..
- Evaluación:Evaluamos el desempeño del modelo comparando sus predicciones en un conjunto de datos de prueba (datos no vistos durante el entrenamiento) con los precios reales.Las métricas de evaluación comunes para las tareas de regresión incluyen el error cuadrático medio (MSE) o el coeficiente de determinación (R cuadrado).
- Aplicación: El modelo entrenado ahora se puede utilizar para predecir los precios de las viviendas en función de su tamaño en aplicaciones del mundo real.
Aquí tienes un ejemplo sencillo de regresión lineal utilizando la biblioteca scikit-learn de Python para predecir los precios de las viviendas en función de su tamaño:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# Sample dataset (house sizes in square feet and prices in rupees)
sizes = np.array([600, 800, 1000, 1200, 1500, 1800]).reshape(-1, 1)
prices = np.array([100000, 150000, 200000, 250000, 300000, 350000])
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(sizes, prices, test_size=0.2, random_state=42)
# Create and train the linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Plot the data and the linear regression line
plt.scatter(sizes, prices, color='blue', label='Actual prices')
plt.plot(sizes, model.predict(sizes), color='red', label='Predicted prices')
plt.xlabel('Size (sq. ft)')
plt.ylabel('Price ($)')
plt.legend()
plt.show()
# Example prediction
house_size = 1400
predicted_price = model.predict([[house_size]])
print(f"Predicted price for a {house_size} sq. ft house: ${predicted_price[0]:,.2f}")
Este es un ejemplo básico para demostrar la regresión lineal. En un escenario real, normalmente se usaría un conjunto de datos más grande y diverso para el entrenamiento y las pruebas, y también se considerarían características adicionales (más allá del tamaño de la vivienda) que podrían influir en los precios de las casas.
- Algoritmos de aprendizaje no supervisado
Los algoritmos de aprendizaje no supervisado se utilizan paraencontrar patrones o estructuras en los datos sin guía explícita o resultados etiquetadosExploran los datos para comprender sus propiedades y descubrir patrones o relaciones ocultas. Los algoritmos comunes incluyen agrupamiento (p. ej., K-means ), reducción de dimensionalidad (p. ej., PCA), aprendizaje de reglas de asociación (p. ej., Apriori) y modelos generativos (p. ej., GAN). El aprendizaje no supervisado se utiliza para tareas como agrupar documentos similares, detectar anomalías, reducir la dimensionalidad para la visualización y generar datos sintéticos.
Aquí tienes un breve ejemplo de cómo se puede utilizar en la práctica el clustering, un tipo de algoritmo de aprendizaje no supervisado:
Imagina que tienes un conjunto de datos con información sobre los clientes de una tienda online, incluyendo datos como edad, ingresos e historial de compras. Quieres agrupar a los clientes con características similares para comprender mejor su comportamiento y adaptar las estrategias de marketing.
- Preprocesamiento de datos : Antes de aplicar la agrupación, normalmente se preprocesan los datos, lo que puede incluir el manejo de valores faltantes, el escalado de características y la codificación de variables categóricas.
- Elección de un algoritmo de agrupamiento : En este caso, decide utilizar el algoritmo de agrupamiento K-means , un algoritmo popular que divide el conjunto de datos en K grupos, donde cada punto de datos pertenece al grupo con la media más cercana.
- Determinación del número de clústeres :Uno de los desafíos en la agrupación K-means es determinar el número óptimo de clústeres (K).Puedes utilizar técnicas como el método del codo o la puntuación de la silueta para encontrar el valor K óptimo.
- Aplicación del algoritmo de agrupamiento K-means : Una vez que haya determinado el número de clústeres, aplique el algoritmo K-means al conjunto de datos preprocesado.El algoritmo asigna iterativamente los puntos de datos al centro del clúster más cercano y actualiza los centros de los clústeres hasta que converge.
- Análisis de los clústeres : Tras la agrupación , puede analizar los clústeres resultantes para comprender los segmentos de clientes. Por ejemplo, podría encontrar clústeres de clientes jóvenes con altos ingresos que realizan compras frecuentes y clústeres de clientes mayores y con presupuestos ajustados que realizan compras ocasionales.
- Adaptación de las estrategias de marketing : Basándose en el análisis de clústeres, puede adaptar las estrategias de marketing a diferentes segmentos de clientes. Por ejemplo, podría ofrecer descuentos al segmento que busca ahorrar o promocionar nuevos productos al segmento de compradores frecuentes.
- Evaluación : Es importante evaluar los resultados de la agrupación para asegurar que sean significativos y útiles. Se pueden utilizar métricas como el coeficiente de silueta o la inspección visual de las asignaciones de clústeres para evaluar la calidad de la agrupación.
Aquí tienes un ejemplo de cómo podrías implementar el algoritmo de agrupamiento K-means en Python utilizando la biblioteca scikit-learn:
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import pandas as pd
import matplotlib.pyplot as plt
# Sample customer data (age, income, purchase history)
data = {
'Age': [25, 30, 35, 20, 45, 50, 60, 55, 70, 65],
'Income': [50000, 60000, 75000, 40000, 90000, 100000, 95000, 110000, 150000, 140000],
'Purchase History': [1, 2, 3, 1, 3, 2, 3, 1, 2, 3]
}
df = pd.DataFrame(data)
# Standardize the features
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df)
# Apply K-means clustering
kmeans = KMeans(n_clusters=3, random_state=42)
df['Cluster'] = kmeans.fit_predict(scaled_data)
# Visualize the clusters
plt.scatter(df['Age'], df['Income'], c=df['Cluster'], cmap='viridis')
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Customer Segmentation')
plt.show()
En este ejemplo, primero estandarizamos las características StandardScalerpara asegurar que cada una contribuya por igual al proceso de agrupamiento. Luego aplicamos el algoritmo K-means n_clusters=3para agrupar a los clientes en tres clústeres según su edad, ingresos e historial de compras. Finalmente, visualizamos los clústeres mediante un diagrama de dispersión, donde cada clúster está representado por un color diferente.
- Algoritmos de aprendizaje por refuerzo
Aprendizaje por refuerzo Los algoritmos de aprendizaje por refuerzo (RL) entrenan a los agentes para tomar decisiones interactuando con un entorno para lograr un objetivo o maximizar una recompensa.Entre los principales algoritmos de aprendizaje por refuerzo se incluyen el aprendizaje Q, las redes neuronales profundas Q (DQN), los métodos de gradiente de política, los métodos actor-crítico y el aprendizaje por diferencia temporal (TD). Estos algoritmos se utilizan en diversas aplicaciones, como juegos, robótica y gestión de recursos.
Aquí tienes un ejemplo sencillo de cómo podrías usar el aprendizaje Q para enseñar a un robot a navegar por un mundo cuadriculado para alcanzar un objetivo:
- Configuración del entorno : Defina un mundo de cuadrícula con una posición inicial, una posición final y obstáculos.
- Inicialización de la tabla Q : Inicializa una tabla Q para almacenar la utilidad esperada de realizar acciones en cada estado. Inicialmente, los valores Q se establecen en cero.
- Formación del agente :
- Comience desde el estado inicial.
- Elija una acción utilizando una política epsilon-greedy (explorar con probabilidad epsilon, explotar con probabilidad 1-epsilon).
- Realiza la acción y observa la recompensa y el nuevo estado.
- Actualiza el valor Q para el par estado-acción actual utilizando la regla de actualización de aprendizaje Q.
- Repita los pasos anteriores hasta alcanzar el estado deseado o el número máximo de pasos.
- Regla de actualización de Q-Learning :
- Q[estado, acción] = Q[estado, acción] + alfa (recompensa + gamma max(Q[nuevo_estado, :]) – Q[estado, acción])
alphaes la tasa de aprendizaje.gammaes el factor de descuento.
- Q[estado, acción] = Q[estado, acción] + alfa (recompensa + gamma max(Q[nuevo_estado, :]) – Q[estado, acción])
- Probando el agente :
- Utilice los valores Q aprendidos para determinar la mejor acción en cada estado.
- Mueva al agente según las mejores acciones hasta que alcance el objetivo o se alcance un número máximo de pasos.
- Visualización : Visualice la trayectoria del agente y los valores Q aprendidos en el mundo de la cuadrícula.
Este ejemplo ilustra los principios básicos del aprendizaje Q. En la práctica, se utilizan algoritmos y técnicas más sofisticadas para problemas más complejos.
Aquí tenéis una implementación sencilla en Python del algoritmo Q-learning para un problema de navegación en un mundo cuadriculado:
import numpy as np
# Define the grid world
GRID_SIZE = 5
START_STATE = (0, 0)
GOAL_STATE = (GRID_SIZE - 1, GRID_SIZE - 1)
OBSTACLES = [(1, 1), (2, 2), (3, 3)]
ACTIONS = ['up', 'down', 'left', 'right']
NUM_EPISODES = 1000
MAX_STEPS = 100
EPSILON = 0.1
ALPHA = 0.1
GAMMA = 0.9
# Initialize Q-table
Q = np.zeros((GRID_SIZE, GRID_SIZE, len(ACTIONS)))
# Helper function to get valid next states
def get_next_states(state):
x, y = state
next_states = []
for action in ACTIONS:
if action == 'up' and x > 0:
next_states.append((x - 1, y))
elif action == 'down' and x < GRID_SIZE - 1:
next_states.append((x + 1, y))
elif action == 'left' and y > 0:
next_states.append((x, y - 1))
elif action == 'right' and y < GRID_SIZE - 1:
next_states.append((x, y + 1))
return next_states
# Q-learning algorithm
for _ in range(NUM_EPISODES):
state = START_STATE
for _ in range(MAX_STEPS):
if state == GOAL_STATE:
break
if np.random.rand() < EPSILON:
action = np.random.choice(ACTIONS)
else:
action = ACTIONS[np.argmax(Q[state[0], state[1]])]
next_states = get_next_states(state)
next_state = next_states[np.random.choice(len(next_states))]
reward = 1 if next_state == GOAL_STATE else -1
Q[state[0], state[1], ACTIONS.index(action)] += ALPHA * (reward + GAMMA * np.max(Q[next_state[0], next_state[1]]) - Q[state[0], state[1], ACTIONS.index(action)])
state = next_state
# Test the learned policy
state = START_STATE
path = [state]
while state != GOAL_STATE:
action = ACTIONS[np.argmax(Q[state[0], state[1]])]
next_states = get_next_states(state)
next_state = next_states[np.argmax([Q[state[0], state[1], ACTIONS.index(a)] for a in ACTIONS])]
state = next_state
path.append(state)
# Print the learned policy and path
print("Learned Q-values:")
print(Q)
print("Optimal path:")
for state in path:
print(state)
Este código define un mundo cuadriculado simple de 5×5 con obstáculos, donde el agente (representado por un robot) aprende a navegar desde el estado inicial hasta el estado objetivo mediante el aprendizaje Q. El agente actualiza sus valores Q en función de las recompensas recibidas y utiliza una política epsilon-greedy para explorar el entorno. Finalmente, la política aprendida se utiliza para encontrar la ruta óptima desde el estado inicial hasta el estado objetivo.
- Algoritmos de aprendizaje evolutivo
Los algoritmos evolutivos (AE) son algoritmos de optimización inspirados en la evolución natural.Mejoran iterativamente las soluciones candidatas a problemas de optimización utilizando operadores de selección, cruce y mutación.Entre los principales algoritmos evolutivos se incluyen los algoritmos genéticos (AG), la programación genética (PG), la evolución diferencial (ED), las estrategias evolutivas (EE), la optimización por enjambre de partículas (PSO) y la optimización por colonia de hormigas (ACO). Estos algoritmos se utilizan en diversas aplicaciones para resolver problemas complejos de optimización y búsqueda.
Aquí tienes un ejemplo sencillo de cómo se puede utilizar un algoritmo evolutivo para resolver un problema de optimización básico, como encontrar el valor máximo de una función:
- Inicialización : Crea una población de soluciones aleatorias, donde cada solución representa un posible orden de las ciudades a visitar. Por ejemplo, si hay 5 ciudades, una solución podría representarse como [1, 3, 2, 4, 5], indicando el orden en que se deben visitar las ciudades.
- Evaluación : Evaluar la aptitud de cada solución en la población. La aptitud podría ser la distancia total recorrida para el orden de ciudades dado.
- Selección : Se seleccionan individuos de la población para que sirvan como progenitores de la siguiente generación. Los individuos se seleccionan con una probabilidad proporcional a su aptitud, por lo que las soluciones con distancias totales más cortas tienen más probabilidades de ser seleccionadas.
- Cruce : Realiza un cruce para crear descendencia a partir de los padres seleccionados. Un método común de cruce para el problema del viajante es el cruce ordenado (OX), que conserva el orden relativo de las ciudades entre los dos padres.
- Mutación : En ocasiones, se aplica una mutación a la descendencia para introducir diversidad. Por ejemplo, se podrían intercambiar dos ciudades en el orden.
- Reemplazo : Reemplazar la población actual con la nueva población de descendientes.
- Terminación : Repita los pasos de selección, cruce, mutación y reemplazo durante un número fijo de generaciones o hasta que se cumpla una condición de terminación (por ejemplo, se alcance el número máximo de generaciones o se logre el nivel de aptitud deseado).
A lo largo de sucesivas generaciones, la población debería evolucionar hasta contener individuos con distancias totales recorridas más cortas, convergiendo finalmente hacia la solución óptima para el problema del viajante.
Aquí se muestra una implementación básica en Python de un algoritmo evolutivo para resolver el Problema del Viajante (TSP) utilizando un método de cruce ordenado (OX) simple para el cruce y una mutación de intercambio:
import random
# Define the cities and their coordinates
cities = {
1: (0, 0),
2: (1, 2),
3: (3, 1),
4: (5, 2),
5: (6, 0)
}
# Calculate the distance between two cities
def distance(city1, city2):
x1, y1 = cities[city1]
x2, y2 = cities[city2]
return ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
# Calculate the total distance of a route
def total_distance(route):
return sum(distance(route[i], route[i + 1]) for i in range(len(route) - 1)) + distance(route[-1], route[0])
# Initialize population
def init_population(population_size, city_count):
return [[city for city in range(1, city_count + 1)] for _ in range(population_size)]
# Perform ordered crossover (OX) between two parent routes
def crossover(parent1, parent2):
start = random.randint(0, len(parent1) - 1)
end = random.randint(start + 1, len(parent1))
offspring = [-1] * len(parent1)
offspring[start:end] = parent1[start:end]
for city in parent2:
if city not in offspring:
for i in range(len(offspring)):
if offspring[i] == -1:
offspring[i] = city
break
return offspring
# Perform swap mutation on a route
def mutate(route):
index1, index2 = random.sample(range(len(route)), 2)
route[index1], route[index2] = route[index2], route[index1]
# Evolutionary algorithm
def evolutionary_algorithm(population_size, city_count, generations):
population = init_population(population_size, city_count)
for _ in range(generations):
offspring = []
for _ in range(population_size // 2):
parent1, parent2 = random.sample(population, 2)
child1 = crossover(parent1, parent2)
child2 = crossover(parent2, parent1)
mutate(child1)
mutate(child2)
offspring.extend([child1, child2])
population = offspring
best_route = min(population, key=total_distance)
return best_route, total_distance(best_route)
# Example usage
population_size = 50
city_count = 5
generations = 1000
best_route, best_distance = evolutionary_algorithm(population_size, city_count, generations)
print("Best Route:", best_route, "Total Distance:", best_distance)
Este código proporciona un marco básico para resolver el problema del viajante mediante un algoritmo evolutivo. Cabe destacar que esta implementación utiliza una representación simple de las rutas como permutaciones de ciudades y podría no ser adecuada para problemas de gran escala.
En conclusión, este capítulo sirve como introducción fundamental al fascinante mundo del aprendizaje automático, guiando a los principiantes a través de los conceptos y técnicas esenciales que sustentan esta tecnología transformadora. Desde comprender el papel crucial de la analítica en el aprendizaje automático hasta explorar los diversos algoritmos que impulsan los modelos predictivos, y destacar la importancia de Python en el desarrollo de estos modelos, nos hemos embarcado en un viaje integral al ámbito de la inteligencia artificial. Al familiarizarnos con los tipos de algoritmos de aprendizaje automático —supervisado, no supervisado, por refuerzo y evolutivo— y sus aplicaciones prácticas, hemos sentado las bases para una exploración e innovación más profundas en los capítulos siguientes. Esta exploración no solo desmitifica las complejas interrelaciones entre IA, ML y DL, sino que también capacita a los estudiantes con el conocimiento necesario para iniciar sus proyectos utilizando la plataforma Anaconda y el rico ecosistema de bibliotecas de Python. A medida que continuamos profundizando en las capacidades y aplicaciones del aprendizaje automático, el potencial para crear soluciones inteligentes e impactantes a problemas del mundo real se vuelve cada vez más tangible.
